

本記事はアフィリエイト広告(PR)を含みます
Stable Diffusionはデフォルト設定で4K画像を出力することを想定していません。
SD1.5で512×512、SDXLでも1024×1024pxが基準の解像度です。
直接4K(3840×2160)を指定することもできますがVRAMの消費が非常に大きいのでGPUのスペックによっては「CUDA out of memory」になってしまうかもしれません。
VRAMが少ないGPUで4K画像を生成するには少し工夫が必要になります。
そこで今回は3種類の4K画像を生成する方法についてまとめました。
実行環境
- OS : Windows 11 Home
- GPU : NVIDIA GeForce RTX 5070 Ti
- Python:3.12 (venv)
- 実行方式:Diffusers

1. 直接指定で生成してみる
まずは直接4Kを指定して生成できるか試してみます。
ちなみに今回は「夜の街並みを写真のように描く」というニュアンスで
cinematic photo of a futuristic tokyo street at night, neon lights, ultra detailed
というプロンプトを指定しました。
1.1. サンプルコード
ソースコードはこちらです。
seedを固定し処理時間の計測も入れました。
from diffusers import StableDiffusionXLPipeline
import torch
import time
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
pipe = StableDiffusionXLPipeline.from_pretrained(
model_id,
torch_dtype=torch.float16,
).to("cuda")
pipe.enable_attention_slicing()
pipe.enable_vae_slicing()
prompt = "cinematic photo of a futuristic tokyo street at night, neon lights, ultra detailed"
#解像度指定(4K)
width, height = 3840, 2160
#seed固定
seed = 1234
generator = torch.Generator(device="cuda").manual_seed(seed)
#処理時間計測開始
start_time = time.time()
image = pipe(
prompt,
num_inference_steps=30,
guidance_scale=6.5,
width=width,
height=height,
generator=generator,
).images[0]
#処理時間計測終了
end_time = time.time()
elapsed = end_time - start_time
image.save("sdxl_4k.png")
print("saved: sdxl_4k.png")
print(f"seed: {seed}")
print(f"time: {elapsed:.2f} sec")① ライブラリ読み込み
from diffusers import StableDiffusionXLPipeline
import torch
import time| ライブラリ | 意味 |
|---|---|
| diffusers | 画像生成用(Stable Diffusion) |
| torch | PyTorch |
| time | 処理時間計測用 |
② モデルID指定
SDXL 1.0を指定しています。
model_id = "stabilityai/stable-diffusion-xl-base-1.0"③ モデル読み込み
pipe = StableDiffusionXLPipeline.from_pretrained(
model_id,
torch_dtype=torch.float16,
).to("cuda")④ VRAM節約設定
pipe.enable_attention_slicing()
pipe.enable_vae_slicing()enable_attention_slicing()はVRAMが節約できる代わりに10%処理速度が下がります。
enable_vae_slicing()はVAEの処理を分割して実行することで、VRAM使用量を抑えるための設定です。
⑤ プロンプト指定
prompt = "cinematic photo of a futuristic tokyo street at night, neon lights, ultra detailed"⑥ 解像度指定(4K)
width, height = 3840, 2160⑦ seed固定
seed = 1234
generator = torch.Generator(device="cuda").manual_seed(seed)⑧ 処理時間計測開始
start_time = time.time()⑨ 画像生成
image = pipe(
prompt,
num_inference_steps=30,
guidance_scale=6.5,
width=width,
height=height,
generator=generator,
).images[0]| 引数 | 意味 |
|---|---|
| num_inference_steps | ノイズ除去回数。 SDXLでは30回が精度と速度のバランスがいいとされている。 |
| guidance_scale | プロンプト忠実度。 6~8がよくつかわれるらしいので今回は6.5あたりを設定する。 |
| generator | seed固定を適用 |
⑩ 処理時間計測終了
end_time = time.time()
elapsed = end_time - start_time⑪ 画像保存
image.save("sdxl_4k.png")⑫ ログ出力
print("saved: sdxl_4k.png")
print(f"seed: {seed}")
print(f"time: {elapsed:.2f} sec")1.2. 実行結果
実行結果はこちらです。
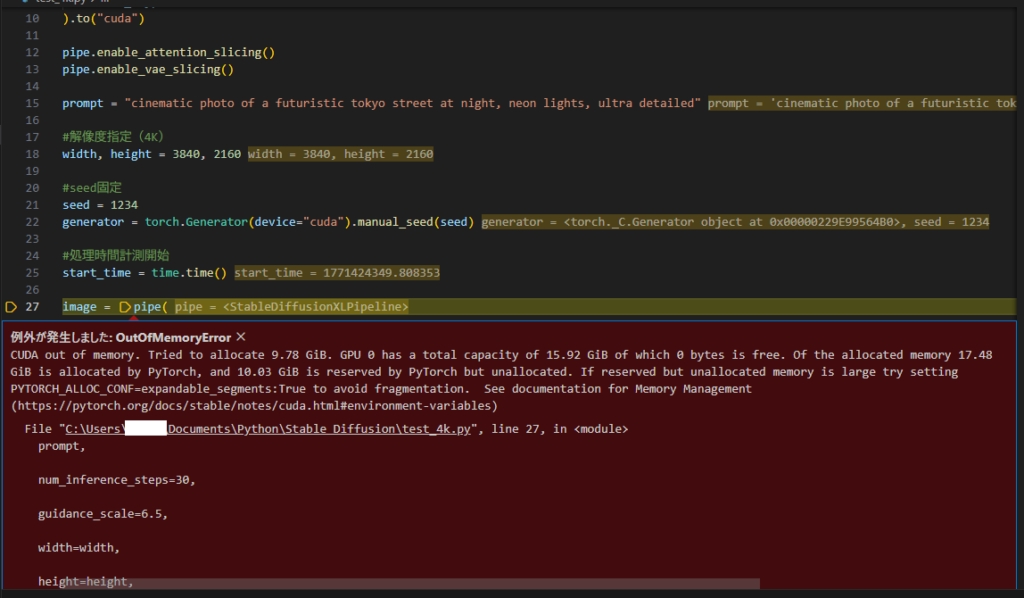
5070 tiをもってしても4K直接出力はメモリが足りませんでした…
2. Resize(補完拡大)
4K画像を直接出力できない場合、小さいサイズで出力してからResizeするという方法があります。
これなら画像生成自体のVRAM消費は抑えて4K出力が可能になります。
2.1. サンプルコード
from diffusers import StableDiffusionXLPipeline
import torch
import time
from PIL import Image
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
pipe = StableDiffusionXLPipeline.from_pretrained(
model_id,
torch_dtype=torch.float16,
).to("cuda")
pipe.enable_attention_slicing()
pipe.enable_vae_slicing()
prompt = "cinematic photo of a futuristic tokyo street at night, neon lights, ultra detailed"
#解像度指定(1024pxに近い解像度)
width, height = 1536, 864
#Resize後の解像度(4K)
width_4K, height_4K = 3840, 2160
#seed固定
seed = 1234
generator = torch.Generator(device="cuda").manual_seed(seed)
#処理時間計測開始
start_time = time.time()
image = pipe(
prompt,
num_inference_steps=30,
guidance_scale=6.5,
width=width,
height=height,
generator=generator,
).images[0]
#Resize
image_4K = image.resize(
(width_4K, height_4K),
resample=Image.LANCZOS # 高品質リサイズ(LANCZOS補間)
)
#処理時間計測終了
end_time = time.time()
elapsed = end_time - start_time
image_4K.save("sdxl_4K_resize.png")
print("saved: sdxl_4K_resize.png")
print(f"seed: {seed}")
print(f"time: {elapsed:.2f} sec")① Pillowインポート
from PIL import ImageResizeを使用するためにライブラリを追加します。
インストールされていない場合はこちらのコマンドでインストールします。
pip install pillow② 解像度指定
width, height = 1536, 864今回は標準1024pxの拡張サイズである1536pxを指定しました。
③ Resize処理
image_4K = image.resize(
(width_4K, height_4K),
resample=Image.LANCZOS # 高品質リサイズ(LANCZOS補間)
)2.2. 実行結果
今回は上手く生成できました。
ぱっと見画質は気になりませんね。

ログはこちら。
生成時間は約13秒でした。
saved: sdxl_4K_resize.png
seed: 1234
time: 13.26 sec3. AIアップスケール
AIアップスケールは画像生成した後、AIによって4Kに拡大する手法です。
通常のリサイズは単純なピクセル拡大なので画質が下がったり、ぼやけた画像になってしまいます。
一方AIによる拡大では、
- AIがディテールを補完
- シャープ&高精細
- 質感などを再現
つまり、単純な補間ではなくAIでディテールを補間しながら拡大するためResizeと比較して高解像度な画像が出力されるということです。
AIアップスケールにもいくつか種類がありますが、今回はReal-ESRGANを使用しました。
Real-ESRGANの環境構築についてはこちらの記事でまとめています。

3.1. サンプルコード
このコードはStable Diffusionで画像生成をした後、Real-ESRGANでアップスケールし、4Kへ縮小して保存します。
Real-ESRGANは4倍など固定倍率のモデルが多いため、今回はなるべく大きめに生成してから拡大・縮小することでなるべく高画質になるようにしています。
import os
import time
from urllib.request import urlretrieve
import cv2
import torch
from PIL import Image
from diffusers import StableDiffusionXLPipeline
from realesrgan import RealESRGANer
from basicsr.archs.rrdbnet_arch import RRDBNet
# =========================================
# 設定
# =========================================
sd_model_id = "stabilityai/stable-diffusion-xl-base-1.0"
prompt = "cinematic photo of a futuristic tokyo street at night, neon lights, ultra detailed"
# SDXL生成サイズ(最初に大きめで生成)
width, height = 1536, 864
# 最終出力サイズ(4K)
final_width, final_height = 3840, 2160
# seed固定
seed = 1234
# Real-ESRGAN設定
realesrgan_model_name = "RealESRGAN_x4plus.pth"
realesrgan_model_url = "https://github.com/xinntao/Real-ESRGAN/releases/download/v0.1.0/RealESRGAN_x4plus.pth"
realesrgan_scale = 4
# ファイル名
sd_output_path = "sdxl.png"
esrgan_output_path = "sdxl_x4.png"
final_output_path = "sdxl_4k_realesrgan.png"
# =========================================
# デバイス設定
# =========================================
device = "cuda" if torch.cuda.is_available() else "cpu"
print("device:", device)
# =========================================
# Stable Diffusion XL パイプライン
# =========================================
print("loading SDXL pipeline...")
pipe = StableDiffusionXLPipeline.from_pretrained(
sd_model_id,
torch_dtype=torch.float16 if device == "cuda" else torch.float32,
)
pipe = pipe.to(device)
# メモリ節約
pipe.enable_attention_slicing()
pipe.enable_vae_slicing()
generator = torch.Generator(device=device).manual_seed(seed)
# =========================================
# Real-ESRGAN モデル準備
# =========================================
if not os.path.exists(realesrgan_model_name):
print("downloading Real-ESRGAN model...")
urlretrieve(realesrgan_model_url, realesrgan_model_name)
print("downloaded:", realesrgan_model_name)
print("building Real-ESRGAN model...")
esrgan_model = RRDBNet(
num_in_ch=3,
num_out_ch=3,
num_feat=64,
num_block=23,
num_grow_ch=32,
scale=realesrgan_scale
)
upsampler = RealESRGANer(
scale=realesrgan_scale,
model_path=realesrgan_model_name,
model=esrgan_model,
tile=0,
tile_pad=10,
pre_pad=0,
half=(device == "cuda"),
device=device,
)
# =========================================
# 1. SDXLで画像生成
# =========================================
print("generating image with SDXL...")
start_total = time.time()
start_sd = time.time()
image = pipe(
prompt=prompt,
num_inference_steps=30,
guidance_scale=6.5,
width=width,
height=height,
generator=generator,
).images[0]
if device == "cuda":
torch.cuda.synchronize()
sd_elapsed = time.time() - start_sd
image.save(sd_output_path)
print("saved:", sd_output_path)
print("SDXL output size:", image.size)
# =========================================
# 2. Real-ESRGANでアップスケール
# =========================================
print("upscaling with Real-ESRGAN...")
img = cv2.imread(sd_output_path, cv2.IMREAD_COLOR)
if img is None:
raise ValueError(f"failed to read image: {sd_output_path}")
start_esrgan = time.time()
output, _ = upsampler.enhance(img, outscale=realesrgan_scale)
if device == "cuda":
torch.cuda.synchronize()
esrgan_elapsed = time.time() - start_esrgan
cv2.imwrite(esrgan_output_path, output)
print("saved:", esrgan_output_path)
print("Real-ESRGAN output size:", output.shape[1], "x", output.shape[0])
# =========================================
# 3. 4Kへ高品質縮小
# =========================================
print("resizing to exact 4K...")
upscaled_pil = Image.open(esrgan_output_path).convert("RGB")
final_image = upscaled_pil.resize(
(final_width, final_height),
resample=Image.LANCZOS
)
final_image.save(final_output_path)
total_elapsed = time.time() - start_total
print("saved:", final_output_path)
print(f"seed: {seed}")
print(f"SDXL time: {sd_elapsed:.2f} sec")
print(f"Real-ESRGAN time: {esrgan_elapsed:.2f} sec")
print(f"total time: {total_elapsed:.2f} sec")長いので主要な部分だけ解説します。
① Stable Diffusion XLのパイプライン読み込み
pipe = StableDiffusionXLPipeline.from_pretrained(
sd_model_id,
torch_dtype=torch.float16 if device == "cuda" else torch.float32,
).to(device)まずはdiffusersライブラリのSDXLパイプラインを読み込みます。
ここで
torch_dtype=torch.float16を指定するとVRAMの消費を減らすことができます。
② 画像生成
image = pipe(
prompt=prompt,
num_inference_steps=30,
guidance_scale=6.5,
width=width,
height=height,
generator=generator,
).images[0]ここでは1536×864の画像を生成しています。
主なパラメータはこちら
| パラメータ | 意味 |
|---|---|
| prompt | 生成する画像の内容 |
| num_inference_steps | 生成ステップ数 |
| guidance_scale | プロンプトへの忠実度 |
| width | 画像の幅 |
| height | 画像の高さ |
③ Real-ESRGANのネットワーク定義
esrgan_model = RRDBNet(
num_in_ch=3,
num_out_ch=3,
num_feat=64,
num_block=23,
num_grow_ch=32,
scale=realesrgan_scale
)次に、Real-ESRGANのネットワーク構造を定義します。
realesrgan_scale=4なので生成された画像を4倍(6144×3456)に拡大します。
④ 画像アップスケール
output, _ = upsampler.enhance(img, outscale=realesrgan_scale)ここで実際にアップスケール処理を行います。
リサイズ処理とは違い、AIでディテールを補完しながら拡大します。
⑤ 4Kサイズへ縮小
final_image = upscaled_pil.resize(
(final_width, final_height),
resample=Image.LANCZOS
)Real-ESRGANでアップスケールされた画像は6144×3456なので、4Kサイズ(3840×2160)へ縮小します。
ここはリサイズ処理と同じLANCZOS補間を使用しています。
3.2. 動作確認
出力結果はこちら。

リサイズは13秒なのに対し、Real-ESRGANによりアップスケールは33秒かかりました。
やはりAIを使う分処理時間は長くなります。
saved: sdxl.png
SDXL output size: (1536, 864)
upscaling with Real-ESRGAN...
saved: sdxl_x4.png
Real-ESRGAN output size: 6144 x 3456
resizing to exact 4K...
saved: sdxl_4k_realesrgan.png
seed: 1234
SDXL time: 13.58 sec
Real-ESRGAN time: 18.50 sec
total time: 33.77 sec800倍に拡大してリサイズと比較してみます。


違いは一目瞭然ですね!
リサイズは拡大するとぼやけて見えるのに対し、Real-ESRGANでアップスケールしたほうは鮮明に描画されています。
4. まとめ
今回はStable Diffusionで4K画像を生成する方法を3種類紹介しました。
直接指定する方法はVRAM消費が大きいため現実的ではありませんが、リサイズやReal-ESRGANを使用した方法であれば実用的なのではないでしょうか。
手軽さを重視するならリサイズ、多少処理時間がかかっても画質を重視するならReal-ESRGANを使用する方法がおすすめです。
今回は以上です。
5. 参考サイト
・v0.3.0: 新しいAPI、安定した拡散パイプライン、低メモリ推論、MPSバックエンド、ONNX
https://github.com/huggingface/diffusers/releases/tag/v0.3.0
・SDXLで画質爆上げ!初心者でもわかるHires.fix完全ガイド
https://unikoukokun.jp/n/neb83efd801ba
・Real-ESRGAN:AIで画像を高品質にアップスケールする方法
https://www.toolify.ai/ja/ai-news-jp/realesrganai%E7%94%BB%E5%83%8F%E9%AB%98%E5%93%81%E8%B3%AA%E6%96%B9%E6%B3%95-3464438
・画像のリサイズを実装する(Lanczos編)
https://hexadrive.jp/hexablog/program/28091/

コメント