

本記事はアフィリエイト広告(PR)を含みます
OpenCVの2値化処理を行う関数には「cv::threshold」がありますが、この関数はとにかく速いです。アルゴリズム自体は閾値を境に画素値を0と1(1Byteなら255)に振り分けるだけなので実装自体は簡単なのですが、ただ実装するだけでは処理速度に雲泥の差が出ます。
OpenCVは内部的に並列処理やSIMD、さらにCPUの最適化なども実装されているので不通に実装しただけでは追いつけません。
そこでOpenCVの設計思想をまねてSIMDとOpenMPを利用した自前の2値化処理を実装し、OpenCVと比較してみようと思います。
※ なお本記事は実装までです。
1. OpenMPとは
C言語やC++向けの共有メモリ並列化APIで、コンパイラ指示(pragma)を使ってforループなどを簡単に並列化できる仕組みのことです。
特に既存コードを大きく変えずに並列化したい場合に強力で、画像処理分野などで広く使われています。
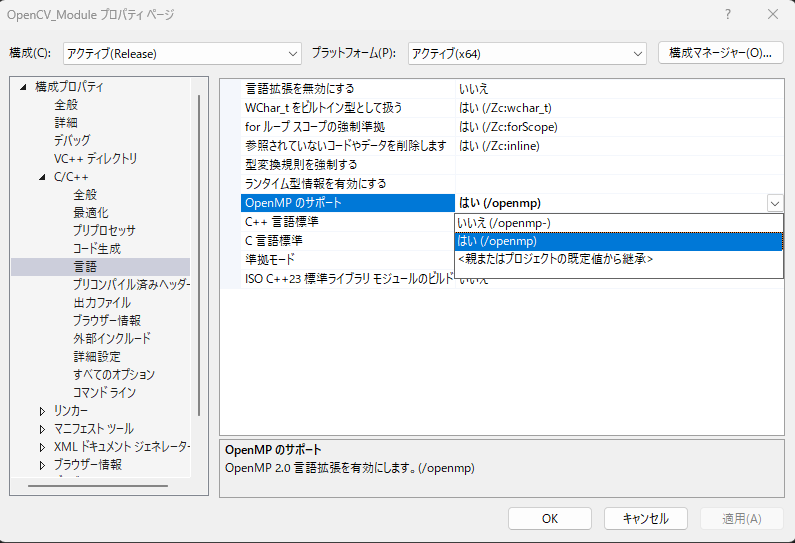
1.1. Visual Studioの設定
プロパティを開き、「C/C++ → 言語 → OpenMPのサポート」を「はい(/openmp)」に設定します。
2.2. サンプルコード
まずは以下のコードでOpenMPを動かしてみます。
#include <iostream>
#ifdef _OPENMP
#include <omp.h>
#endif
int main(void){
#ifdef _OPENMP
#pragma omp parallel
{
int tid = omp_get_thread_num();
int nthreads = omp_get_num_threads();
#pragma omp critical
{
std::cout << "Hello from thread "
<< tid << " / " << nthreads << std::endl;
}
}
#else
std::cout << "OpenMP is NOT enabled" << std::endl;
#endif
return 0;
}実行結果はこちら。
Hello from thread 0 / 20
Hello from thread 1 / 20
Hello from thread 2 / 20
Hello from thread 9 / 20
Hello from thread 3 / 20
Hello from thread 4 / 20
Hello from thread 5 / 20
Hello from thread 6 / 20
Hello from thread 7 / 20
Hello from thread 8 / 20
Hello from thread 10 / 20
Hello from thread 11 / 20
Hello from thread 12 / 20
Hello from thread 13 / 20
Hello from thread 14 / 20
Hello from thread 15 / 20
Hello from thread 16 / 20
Hello from thread 17 / 20
Hello from thread 19 / 20
Hello from thread 18 / 202. SIMDとは
SIMD(シムディー)はSingle Instruction Multiple Dataの略で、1つの命令で複数のデータを同時に処理するというCPUの仕組みです。
128bitや256bitなどの巨大なデータを一括で処理できるようになるので処理速度の向上が期待できます。
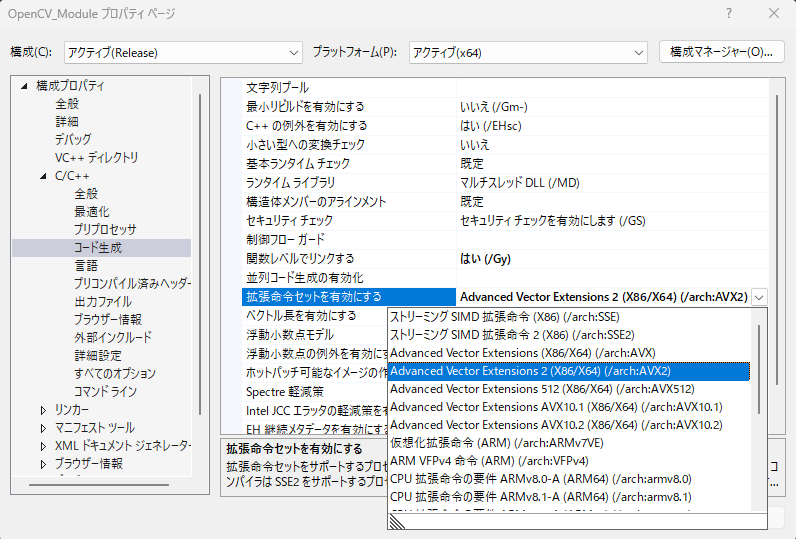
2.1. Visual Studioの設定
プロパティを開き、「C/C++ → コード生成 → 拡張命令セットを有効にする」を「Advanced Vector Extensions 2(X86/X64)(/arch:AVX2)」に設定します。
2.2. CPU命令セットの定義
まずはどのCPU命令セットが使える環境かを定義します。
#if defined(_MSC_VER)
#include <intrin.h>
#endif
#if defined(__AVX2__) || defined(_M_AVX2)
#include <immintrin.h>
#elif defined(__SSE2__) || defined(_M_X64) || (defined(_M_IX86_FP) && _M_IX86_FP >= 2)
#include <emmintrin.h>
#endif
#if defined(__ARM_NEON) || defined(_M_ARM64)
#include <arm_neon.h>
#endif「if defined(_MSC_VER)」はMSVCでコンパイルしているかの判定で、Visual Studioを使用する場合はTRUEになります。
CPU命令セットはSSE2、AVX2、ARM NEONの判定が入っています。
| 規格名 | 対象CPU | 判定用マクロ | 一度に処理可能なbit数 | 特徴 |
|---|---|---|---|---|
| SSE2 | Intel/AMD | __SSE2__ | 128bit(16画素) | 2000年代前半から普及している「標準装備」。ほぼ全てのPCで動作する |
| AVX2 | Intel/AMD | __AVX2__ | 256bit(32画素) | 2013年以降のCPUに搭載。SSEの倍の速度が出る、現代のPCでのメイン武器。 |
| ARM NEON | ARM(スマホ、Mac) | __ARM_NEON | 128bit(16画素) | iPhone、Android、Apple M1/M2チップ等で使われる高速化規格。 |
| _M_X64 | Windows(x64) | _M_X64 | MSVC専用マクロ。64bit環境であることを示し、SSE2が確実にある前提で動ける。 |
2.3. 8bit用SIMDラッパー構造体(v_uint8)の実装
まずはラッパー構造体を実装します。
これによりCPUごとにSIMD命令(AVX2、SSE2など)を意識せず共通のコードで実行できます。
struct v_uint8
{
#if defined(__AVX2__) || defined(_M_AVX2)
static constexpr int lanes = 32;
__m256i val;
v_uint8() = default;
explicit v_uint8(__m256i v) : val(v) {}
#elif defined(__SSE2__) || defined(_M_X64) || (defined(_M_IX86_FP) && _M_IX86_FP >= 2)
static constexpr int lanes = 16;
__m128i val;
v_uint8() = default;
explicit v_uint8(__m128i v) : val(v) {}
#elif defined(__ARM_NEON) || defined(_M_ARM64)
static constexpr int lanes = 16;
uint8x16_t val;
v_uint8() = default;
explicit v_uint8(uint8x16_t v) : val(v) {}
#else
static constexpr int lanes = 16;
uchar val[lanes];
#endif
};この構造体の中は以下の通りです。
① CPUに応じてレジスタ型を切り替えています
- AV2 : __m256i(32画素)
- SSE2 : __m128i(16画素)
- NEON : uint8x16_t(16画素)
② 同時に処理できる画素数をlanesに持たせています
これによりCPUに合わせて自動でループ幅を変更できます。
- static constexpr int lanes = 32; // AVX2
- static constexpr int lanes = 16; // SSE2 / NEON
③ SIMDがない環境でも動くようにします
- uchar val[lanes];
2.4. ブロードキャスト関数(vx_setall_u8)の実装
8bit値をSIMDレジスタの全レーンに同じ値として詰めるブロードキャスト関数を実装します。
static inline v_uint8 vx_setall_u8(uchar x)
{
#if defined(__AVX2__) || defined(_M_AVX2)
// 32 lanes に同じ 8bit 値をブロードキャスト
return v_uint8(_mm256_set1_epi8((char)x));
#elif defined(__SSE2__) || defined(_M_X64) || (defined(_M_IX86_FP) && _M_IX86_FP >= 2)
// 16 lanes
return v_uint8(_mm_set1_epi8((char)x));
#elif defined(__ARM_NEON) || defined(_M_ARM64)
// 16 lanes
return v_uint8(vdupq_n_u8(x));
#else
// Portable fallback
v_uint8 r;
for (int i = 0; i < v_uint8::lanes; ++i)
r.val[i] = x;
return r;
#endif
}SIMDではスカラー値とベクトル値をそのまま比較できないので「thresh=128」と「v0=[p0,p1…pN]」を比較するには
thresh_u=[128,128,…,128]
のようなベクトルが必要になります。
vx_setall_u8はそのベクトルを作成するための関数です。
2.5. SIMD比較関数(v_lt)の実装
各レーンごとにa<bを判定し、結果をマスクとして返すSIMD比較関数を実装します。
static inline v_uint8 v_lt(const v_uint8& a, const v_uint8& b)
{
#if defined(__AVX2__) || defined(_M_AVX2)
// x86の8bit比較は signed なので、unsigned比較にするため 0x80 を XOR してレンジをずらす
const __m256i bias = _mm256_set1_epi8((char)0x80);
__m256i ax = _mm256_xor_si256(a.val, bias);
__m256i bx = _mm256_xor_si256(b.val, bias);
// (a < b) は (b > a) と同値。signed compare を使う
__m256i mask = _mm256_cmpgt_epi8(bx, ax); // 0xFF or 0x00 per lane
return v_uint8(mask);
#elif defined(__SSE2__) || defined(_M_X64) || (defined(_M_IX86_FP) && _M_IX86_FP >= 2)
const __m128i bias = _mm_set1_epi8((char)0x80);
__m128i ax = _mm_xor_si128(a.val, bias);
__m128i bx = _mm_xor_si128(b.val, bias);
__m128i mask = _mm_cmpgt_epi8(bx, ax); // 0xFF or 0x00 per lane
return v_uint8(mask);
#elif defined(__ARM_NEON) || defined(_M_ARM64)
// NEON は unsigned compare が素直に使える(a < b)
// 環境によって vcltq_u8 が無い場合は vcgtq_u8(b,a) で代替可能
#if defined(__aarch64__) || defined(_M_ARM64)
uint8x16_t mask = vcltq_u8(a.val, b.val); // 0xFF or 0x00
return v_uint8(mask);
#else
uint8x16_t mask = vcgtq_u8(b.val, a.val); // (a < b) == (b > a)
return v_uint8(mask);
#endif
#else
v_uint8 r;
for (int i = 0; i < v_uint8::lanes; ++i)
r.val[i] = (a.val[i] < b.val[i]) ? 0xFF : 0x00;
return r;
#endif
}SIMDではTRUE/FALSEを0xFF/0x00で返すのが一般的です。
こうしておくと
result = mask & maxval;だけで
- TRUE : maxval
- FALSE : 0
が分岐なしで実現できます。
またx86の8bit比較は符号付比較しかできないので128を超えた場合に負の値になってしまいます。
そこでXORを使うことで0~255の範囲に調整しています。
__m256i ax = _mm256_xor_si256(a.val, bias);
__m256i bx = _mm256_xor_si256(b.val, bias);2.6. SIMDレジスタ同士のAND関数(v_and)の実装
各レーンごとに「a & b」を計算し、その結果をSIMDベクトルとして返すAND関数を実装します。
static inline v_uint8 v_and(const v_uint8& a, const v_uint8& b)
{
#if defined(__AVX2__) || defined(_M_AVX2)
return v_uint8(_mm256_and_si256(a.val, b.val));
#elif defined(__SSE2__) || defined(_M_X64) || (defined(_M_IX86_FP) && _M_IX86_FP >= 2)
return v_uint8(_mm_and_si128(a.val, b.val));
#elif defined(__ARM_NEON) || defined(_M_ARM64)
return v_uint8(vandq_u8(a.val, b.val));
#else
v_uint8 r;
for (int i = 0; i < v_uint8::lanes; ++i)
r.val[i] = (uchar)(a.val[i] & b.val[i]);
return r;
#endif
}2値化では
- a : 比較結果のマスク(0xFF/0x00)
- b : 最大値ベクトル
なのでmaxvalと0の判別を分岐処理なしかつ一発で決まります。
① AVX2 (256bit)
_mm256_and_si256(a.val, b.val)256bit整数レジスタ同士のAND
② SSE2 (128bit)
_mm_and_si128(a.val, b.val)128bit整数レジスタ同士のAND
③ ARM NEON (128bit)
vandq_u8(a.val, b.val)8bit×16レーン同士のAND
④ SIMDなし
r.val[i] = a.val[i] & b.val[i];1画素ずつのAND
2.7. SIMDレジスタの画素をメモリへ出力する関数(v_store)の実装
SIMDで計算したデータをucharに出力する関数を実装します。
static inline void v_store(uchar* p, const v_uint8& a)
{
#if defined(__AVX2__) || defined(_M_AVX2)
_mm256_storeu_si256(reinterpret_cast<__m256i*>(p), a.val);
#elif defined(__SSE2__) || defined(_M_X64) || (defined(_M_IX86_FP) && _M_IX86_FP >= 2)
_mm_storeu_si128(reinterpret_cast<__m128i*>(p), a.val);
#elif defined(__ARM_NEON) || defined(_M_ARM64)
vst1q_u8(p, a.val);
#else
std::memcpy(p, a.val, v_uint8::lanes);
#endif
}SIMDではレジスタの中で処理を行いますが、最終的には配列に戻す必要があります。
① AVX2 (32Byte書き込み)
_mm256_storeu_si256(reinterpret_cast<__m256i*>(p), a.val);a.valの32Byteをp(ポインタ)にまとめて書き込みます。
_storeu_のuは非アライン対応でpが32Byteそろってなくてもいいという意味です。
② SSE2(16Byte書き込み)
_mm_storeu_si128(reinterpret_cast<__m128i*>(p), a.val);16Byteをまとめて書き込みます(非アライン対応)
③ ARM NEON(16Byte書き込み)
vst1q_u8(p, a.val);16Byteをまとめて書き込みます。
④ SIMDなし
std::memcpy(p, a.val, v_uint8::lanes);lanesバイト分をmemcpyで書き込みます。
reinterpret_cast<__m256i*>はstrict aliasingの観点では注意が必要ですが、SIMD intrinsicは実質的に生のメモリストア命令へ展開されるため、OpenCVやEigenなどでも同様の書き方が広く使われています。
アラインメントを保証できない場合は_mm256_storeu_si256を使うのが安全です。
2.8. VTraitsテンプレートの実装
VTraitsはSIMDの型を指定せずに取り出せるようにする仕組みです。
2値化処理では必要になるので実装しておきます。
template<typename V>
struct VTraits; // primary template(未定義)
template<>
struct VTraits<v_uint8>
{
using lane_type = unsigned char;
static inline int vlanes()
{
return v_uint8::lanes;
}
};一応、未対応型を使ったときにコンパイルエラーにするためにprimary templateを未定義にしておきます。
3. 2値化処理実装
ここからは2値化処理を実装していきます。
3.1. 範囲分割関数の実装
入力した画像を分割して並列処理させるため、まずは分割範囲を計算する関数を実装します。
struct Range {
int start;
int end;
};
static inline Range computeRange(
int id, // 分割番号(sr.start)
int id_end, // sr.end(通常は id+1)
int wholeStart, // wholeRange.start
int wholeEnd, // wholeRange.end
int nstripes // 分割数
) {
const int len = wholeEnd - wholeStart;
Range r;
r.start = wholeStart + (int)(((uint64_t)id * len + nstripes / 2) / nstripes);
if (id_end >= nstripes) r.end = wholeEnd;
else r.end = wholeStart + (int)(((uint64_t)id_end * len + nstripes / 2) / nstripes);
return r;
}まず、分割開始位置と終了位置を格納するRange構造体を定義します。
struct Range {
int start;
int end;
};computeRangeは画像[wholeStart,wholeEnd]をnstripes個に分割し、id番目の担当範囲を返す関数です。
| 引数 | 意味 |
|---|---|
| id | 自分の分割番号 |
| id_end | 通常はid+1 |
| wholeStart | 全体の開始位置(0行目) |
| wholeEnd | 全体の終了位置(rows) |
| nstripes | 分割数 |
① 全体の長さ
const int len = wholeEnd - wholeStart;② startの計算
r.start = wholeStart +
((uint64_t)id * len + nstripes / 2) / nstripes;割り算の誤差や整数除算の偏りを減らすためにnstripes/2を足して丸めています。
③ endの計算
if (id_end >= nstripes)
r.end = wholeEnd;
else
r.end = wholeStart +
((uint64_t)id_end * len + nstripes / 2) / nstripes;最後のidはwholeEndまで担当させます。
それ以外はstartと同じ。
3.2. 2値化処理実装
次に2値化処理を実装します。
void parallel_threshold(cv::Mat& mat_src, cv::Mat& mat_dst, uchar thresh, uchar maxval, int id, int nstripes) {
Range r = computeRange(id, id + 1, 0, mat_src.rows, nstripes);
cv::Mat srcStripe = mat_src.rowRange(r.start, r.end);
cv::Mat dstStripe = mat_dst.rowRange(r.start, r.end);
const int lanes = VTraits<v_uint8>::vlanes();
v_uint8 thresh_u = vx_setall_u8(thresh);
v_uint8 maxval_u = vx_setall_u8(maxval);
if (srcStripe.isContinuous() && dstStripe.isContinuous())
{
const int total = (int)srcStripe.total(); // 画素数
const uchar* src = srcStripe.ptr<uchar>(0);
uchar* dst = dstStripe.ptr<uchar>(0);
int j = 0;
for (; j <= total - lanes; j += lanes)
{
v_uint8 v0 = vx_load(src + j);
v0 = v_lt(thresh_u, v0);
v0 = v_and(v0, maxval_u);
v_store(dst + j, v0);
}
// 端数
for (; j < total; ++j)
dst[j] = (src[j] > thresh) ? maxval : 0;
return;
}
for (int i = 0; i < srcStripe.rows; ++i)
{
const uchar* src = srcStripe.ptr<uchar>(i);
uchar* dst = dstStripe.ptr<uchar>(i);
int j = 0;
for (; j <= srcStripe.cols - lanes; j += lanes)
{
v_uint8 v0 = vx_load(src + j);
v0 = v_lt(thresh_u, v0);
v0 = v_and(v0, maxval_u);
v_store(dst + j, v0);
}
for (; j < srcStripe.cols; ++j)
dst[j] = (src[j] > thresh) ? maxval : 0;
}
}処理の流れは以下の通りです。
- 範囲分割
- 行Mat作成
- SIMDで処理
- 端数の計算
① 担当範囲を決める
Range r = computeRange(id, id + 1, 0, mat_src.rows, nstripes);画像の全行をnstripes個の分割し、id番目が担当する行範囲を取得します。
つまり、この関数は画像全体ではなく担当行のみ処理します。
② 担当範囲の画像を参照
cv::Mat srcStripe = mat_src.rowRange(r.start, r.end);
cv::Mat dstStripe = mat_dst.rowRange(r.start, r.end);rowRange()はコピーではなく参照です。
r.start~r.endまで参照してsrcStripe、dstStripeに渡します。
③ SIMDの準備
const int lanes = VTraits<v_uint8>::vlanes();
v_uint8 thresh_u = vx_setall_u8(thresh);
v_uint8 maxval_u = vx_setall_u8(maxval);レーン数と定数ベクトルを設定し、SIMD関数に渡します。
lanesは一度に処理できる画素数(Byte数)、thresh_uは閾値ベクトル、maxval_uは最大値ベクトルになります。
④ メモリが連続している場合
if (srcStripe.isContinuous() && dstStripe.isContinuous())
{
const int total = (int)srcStripe.total();
const uchar* src = srcStripe.ptr<uchar>(0);
uchar* dst = dstStripe.ptr<uchar>(0);
int j = 0;
for (; j <= total - lanes; j += lanes)
{
v_uint8 v0 = vx_load(src + j);
v0 = v_lt(thresh_u, v0);
v0 = v_and(v0, maxval_u);
v_store(dst + j, v0);
}
for (; j < total; ++j)
dst[j] = (src[j] > thresh) ? maxval : 0;
return;
}isContinuous()がTrueの場合、2次元画像を1次元配列として扱います。
これによりループ回数が減るので処理速度が高速化します。
ここでは以下のような処理を行います。
- vx_loadでsrc[j,…j+lanes-1]をSIMDレジスタへ読み込む
- v_ltでthresh < pixelを判定し、0xFF/0x00を返す
- v_andで2値化(maxval/0)
- v_storeでSIMDレジスタからdst[j,…j+lanes-1]へ出力
⑤ 端数処理
dst[j] = (src[j] > thresh) ? maxval : 0;OpenCVではLUTを作成して処理していますが、今回は1ch8bit限定なのでそのまま処理します。
連続メモリの場合はここまでです。
⑥ メモリが連続していない場合(ROIなど)
for (int i = 0; i < srcStripe.rows; ++i)
{
const uchar* src = srcStripe.ptr<uchar>(i);
uchar* dst = dstStripe.ptr<uchar>(i);
int j = 0;
for (; j <= srcStripe.cols - lanes; j += lanes)
{
v_uint8 v0 = vx_load(src + j);
v0 = v_lt(thresh_u, v0);
v0 = v_and(v0, maxval_u);
v_store(dst + j, v0);
}
for (; j < srcStripe.cols; ++j)
dst[j] = (src[j] > thresh) ? maxval : 0;
}
部分画像(ROI)の処理を行う場合は行ごとに先頭ポインタを渡して処理します。
3.3. OpenMPによる並列化
次にparallel_thresholdを並列処理させる関数を実装します。
void custom_threshold(cv::Mat& mat_src, cv::Mat& mat_dst, uchar thresh, uchar maxval) {
mat_dst.create(mat_src.size(), mat_src.type());
int nstripes = (int)std::max(1.0, mat_dst.total() / (double)(1 << 16));
#pragma omp parallel for schedule(static)
for (int i = 0; i < nstripes; i++) parallel_threshold(mat_src, mat_dst, thresh, maxval, i, nstripes);
}① 出力画像の領域確保
mat_dst.create(mat_src.size(), mat_src.type());mat_srcと同じサイズ、同じ型でmat_dstを作成します。
② 分割数の計算
int nstripes = (int)std::max(1.0, mat_dst.total() / (double)(1 << 16));mat_dst.total()は総画素数、1<<16は65536、つまり約65536画素ごとに処理するように分割数を決めます。
1920×1080の画像なら
となります(最小値は1.0)。
分割数は8や16のような固定値も設定できますが、OpenCVでも同様の計算方法なので合わせました。
③ OpenMPによる並列処理
#pragma omp parallel for schedule(static)
for (int i = 0; i < nstripes; i++)
parallel_threshold(mat_src, mat_dst, thresh, maxval, i, nstripes);iが分割番号で、各スレッドがparallel_thresholdを呼び出しそれぞれの担当範囲を計算します。
schedule(static)を指定すると、ループ反復が事前に固定配分され、スケジューリングのオーバーヘッドが減り、画像処理のような均一負荷の処理では性能と再現性が安定します。
4. 動作確認
実際に2値化ができるか、今回はこちらの画像で試してみます。
最初にAVX2が有効か確認し、グレースケール変換をしてから自作関数とOpenCVそれぞれで2値化処理をしてから一致しているかを比較しています。
#include <iostream>
#include "main.h"
#include <opencv2/opencv.hpp>
int main(void) {
cv::Mat mat_img = cv::imread("shimons_labo.png");
cv::Mat mat_gray;
cv::Mat mat_bin[2];
uchar thresh = 128;
uchar maxval = 255;
// AVX2が有効か確認
#if defined(__AVX2__)
std::cout << "AVX2 enabled\n";
#elif defined(__SSE2__)
std::cout << "SSE2 enabled\n";
#else
std::cout << "No SIMD\n";
#endif
// グレースケール変換
cv::cvtColor(mat_img, mat_gray, cv::COLOR_BGR2GRAY);
// 2値化処理(OpenMP)
custom_threshold(mat_gray, mat_bin[0], thresh, maxval);
cv::threshold(mat_gray, mat_bin[1], thresh, maxval, cv::THRESH_BINARY);
cv::Mat mat_diff;
cv::compare(mat_bin[0], mat_bin[1], mat_diff, cv::CMP_NE); // 不一致 = 255
if (cv::countNonZero(mat_diff) == 0) std::cout << "一致しています\n";
else std::cout << "一致していません\n";
cv::imshow("OpenMP", mat_bin[0]);
cv::imshow("OpenCV", mat_bin[1]);
cv::waitKey(0);
return 0;
}実行結果はこちら。


AVX2 enabled
一致していますOpenCVと同じ結果が得られたことが確認できました。
次回は処理速度を比較してみます。
今回は以上です。

5. 参考サイト
・OpenCVのGitHub
https://github.com/opencv/opencv
・OpenMP
https://www.openmp.org
・【シムディーと読もう!】SIMDによる高速化の実装方法3選(note)
https://note.com/munpei/n/nfd474c78cfe7
・Intel® Intrinsics Guide
https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html
・Microsoft Learn Predefined macros
https://learn.microsoft.com/en-us/cpp/preprocessor/predefined-macros?view=msvc-170
・OpenCVドキュメント
https://docs.opencv.org/4.x/df/d91/group__core__hal__intrin.html


コメント